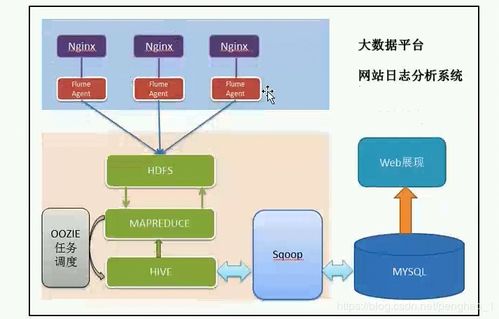
在當今大數據時代,Hadoop已成為構建強大、可擴展數據處理和存儲系統的核心基礎架構。它通過一套開源軟件框架,為處理海量數據集提供了可靠的解決方案,尤其適用于商業智能、科學計算、日志分析等復雜場景。
一、Hadoop核心組件與基礎架構
Hadoop的基礎架構主要建立在兩大核心組件之上:
- Hadoop分布式文件系統(HDFS):作為存儲層,它將大規模數據集分割成多個數據塊,并分布存儲在一個集群的多個計算節點上。其高容錯性設計確保了即使單個節點失效,數據也不會丟失,同時支持流式數據訪問,非常適合一次寫入、多次讀取的場景。
- MapReduce:這是Hadoop的計算引擎,采用“分而治之”的思想。它將計算任務分解為Map(映射)和Reduce(歸約)兩個階段。Map階段并行處理各個數據塊,生成中間結果;Reduce階段則匯總這些中間結果,生成最終輸出。這種模型簡化了分布式編程的復雜性。
圍繞這兩大核心,現代Hadoop生態系統還包括了YARN(資源調度與管理框架)、HBase(分布式數據庫)、Hive(數據倉庫工具)、Spark(內存計算引擎)等一系列服務與工具,共同構成了一個完整的數據處理平臺。
二、構建“好程序”的設計原則
在Hadoop平臺上開發高效、可靠的“好程序”,需要遵循以下關鍵原則:
- 數據本地化:盡可能將計算任務調度到存儲數據的節點上執行,最大限度地減少網絡傳輸開銷,這是提升性能的關鍵。
- 容錯與魯棒性:程序設計應能優雅地處理節點故障。得益于HDFS的數據冗余和MapReduce的任務重試機制,開發者可以專注于業務邏輯,而無需過度擔憂底層硬件故障。
- 水平擴展性:程序應能無縫利用新增的計算和存儲節點。通過增加機器而非升級單機性能來提升處理能力,是Hadoop架構的根本優勢。
- 批處理優化:針對Hadoop經典的批處理模式,程序應設計為適合處理大規模靜態數據集,并充分利用I/O和CPU的并行能力。
三、全面的數據處理與存儲支持服務
Hadoop不僅僅是一個計算框架,它提供了一整套支持服務,使得數據處理和存儲變得高效、靈活且經濟:
- 海量存儲服務:HDFS能夠以極低的成本(使用商用硬件)存儲PB甚至EB級別的數據,為歷史數據分析和數據湖建設提供了堅實基礎。
- 多樣化計算服務:除了批處理的MapReduce,通過YARN的資源管理,集群可以同時運行Spark進行實時/近實時分析、運行Tez優化Hive查詢、運行Flink處理流數據等,滿足不同延遲和吞吐量的需求。
- 數據管理與訪問服務:Hive提供了類SQL的查詢接口,降低了數據分析的門檻;HBase支持低延遲的隨機讀寫;Sqoop和Flume簡化了與關系數據庫及日志系統的數據交換。
- 資源與作業調度服務:YARN作為集群的“操作系統”,負責統一管理計算資源(CPU、內存),并在多用戶、多應用間進行公平、高效的調度,確保集群資源得到充分利用。
- 高可用與安全服務:通過NameNode高可用、數據加密、Kerberos認證及細粒度訪問控制(如Apache Ranger)等機制,為企業級應用提供了必要的可靠性和安全保障。
結論
Hadoop基礎架構通過其分布式存儲與計算的核心設計,為構建處理海量數據的“好程序”提供了理想的土壤。其豐富的生態系統和全面的支持服務,使得它能夠靈活應對從離線批處理到交互式查詢等多種數據處理范式。盡管如今云原生和實時處理技術不斷發展,Hadoop作為大數據領域的奠基者,其核心思想與架構依然在眾多現代數據平臺中發揮著不可替代的作用,是企業和組織實現數據驅動決策的強大后盾。